Nimble: Lightweight and parallel gpu task scheduling for deep learning
简介
Nimble 构建在 PyTorch 之上��,支持训练和推理。
limitations: 论文中提及的算法仅支持静态计算图(也即是用 TorchScript 描述的计算图),不支持动态计算图(输入/权重形状不可变)。理论上感觉不错,考虑的问题太少了,比如让并行最大化,并不一定是最优解(可能还需要引入 cost 来估计利用率)。
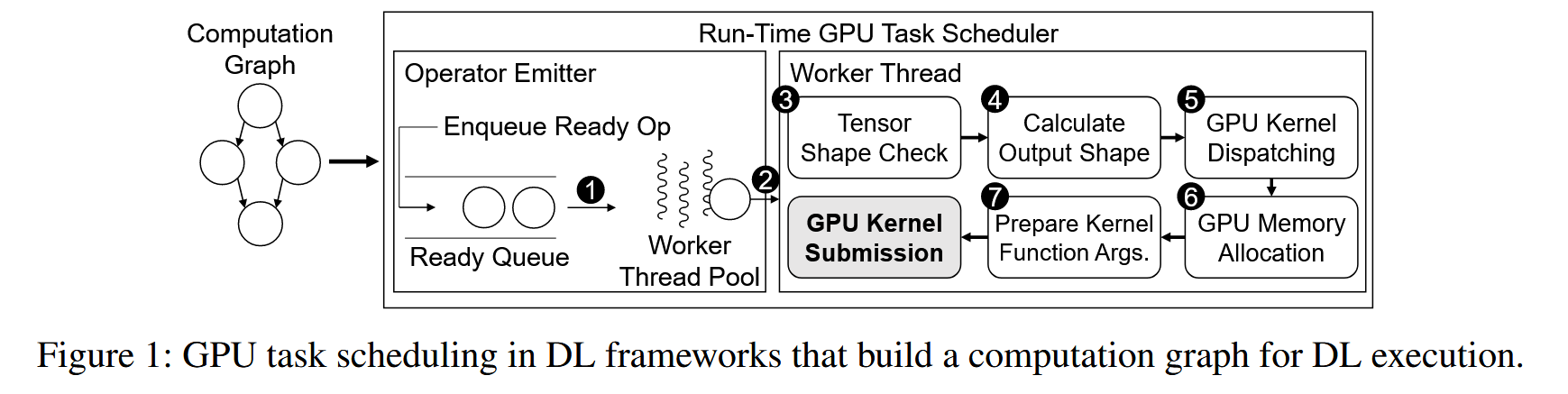
Nimble 基于以下观察:1)调度时间开销太大(这里的调度和 kernel launch 不同,主要指 CPU 侧的一些开销,如下图,一些 check 和准备啥的开销) 2)串行执行 GPU tasks,利用率低,有更多的机会进行并行。
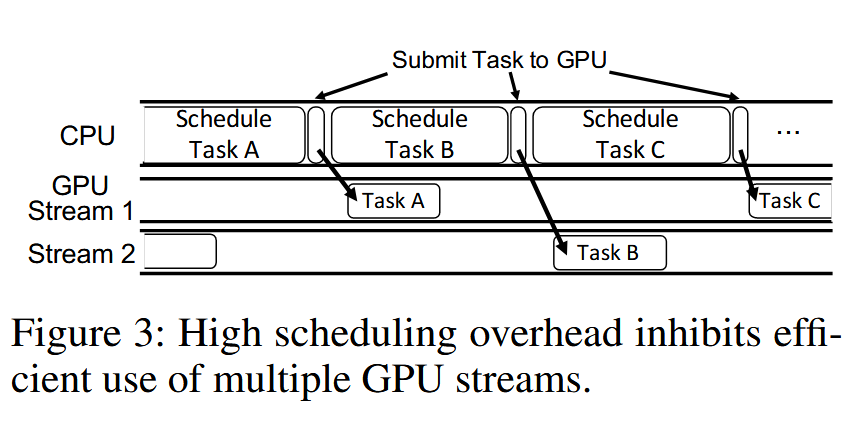
一个简单的办法就是将 GPU Task 放在不同 stream 里面去执行。作者同时观察到这样有个问题:schedule 的时间太长了,多 stream 也没用(如下图),所以要解决 schedule 开销。同时还有确定如何插入同步原语保证 Task 没有依赖可以同步进行。
AoT schedule
作者提出用 AoT (ahead of time) 方式调度任务来节省 schedule 的开销。基于:每论迭代跑的计算图都一样的前提,那么我只需要跑一次(pre-run)然后通过 hook 或者其他什么手段(文章中说是 intercepts 一些调用来记录执行的 task trace)。这样就可以知道整个计算图的信息,下一个迭代回放这些任务就行,不需要额外操作 check 啥的。

作者还提到可以预先分配内存方式来提高性能(类似内存池,运行时捞一个固定内存地址就行)。
Stream assignment algorithm
解决了 schedule 开销问题之后,作者讨论了如何处理依赖关系(即哪些可以并行,哪里要同步)。算法目的:1. 最大逻辑并行数量(这里感觉并不是并行越多效率越高)2. 最小同步数量。
算法如图所示(比较经典,先将图转为最小等价图、然后直接FF最大流解决二分图最大匹配问题):
